Desafio SRE – Primeira Parte

Desafio SRE – Primeira Parte
Contexto do Desafio
O objetivo desta primeira etapa foi:
- Rodar a aplicação localmente
- Dockerizar a aplicação
- Orquestrar App + Redis + PostgreSQL
- Publicar a imagem em um registry
- Provisionar um cluster Kubernetes local com KIND via Terraform
- Subir toda a stack no Kubernetes
- Expor a aplicação via Ingress
- Implementar monitoramento com Prometheus e Grafana
- Criar ServiceMonitor e regras de alerta baseadas no método GOLD
Dockerização da Aplicação
Nesta etapa você transformou a aplicação Python em uma aplicação totalmente containerizada, definindo todas as dependências, ambiente e forma de execução.
Você utilizou um Dockerfile próprio e um docker-compose.yml para orquestrar o app + Redis + Postgres.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
FROM python:3.11-slim
WORKDIR /app
RUN apt-get update && apt-get install -y gcc libpq-dev && \
pip install --no-cache-dir \
Flask==2.0.3 \
Werkzeug==2.3.8 \
prometheus-client==0.13.1 \
prometheus-flask-exporter==0.18.7 \
psycopg2-binary==2.9.7 \
redis==4.5.4 && \
apt-get remove -y gcc && apt-get autoremove -y && apt-get clean
COPY . .
EXPOSE 5000
CMD ["python", "app.py"]
| Etapa | Descrição |
|---|---|
FROM python:3.11-slim |
Imagem base leve, ideal para produção. |
WORKDIR /app |
Define o diretório onde o código ficará dentro do container. |
| Instalação de dependências | GCC e libpq-dev necessários para compilar bibliotecas Python como psycopg2. |
| Instalando libs | Flask, Redis, Prometheus exporter, Postgres driver. |
| Limpeza | Remove GCC para reduzir tamanho final da imagem. |
COPY . . |
Copia seu código-fonte para dentro do container. |
EXPOSE 5000 |
Porta onde sua aplicação Flask vai rodar. |
CMD ["python", "app.py"] |
Comando final: inicia o servidor Flask. |
Build da imagem Docker
Execute no diretório onde está o Dockerfile:
1
docker build -t app-elven:latest .
docker-compose.yml – Explicação Completa
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
version: '3.9'
services:
app-elven:
build:
context: .
dockerfile: Dockerfile
ports:
- 5001:5000
- 9999:9999
networks:
- elven
environment:
- POSTGRES_HOST=db
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=senhafacil
- REDIS_HOST=redis
volumes:
- .:/app
depends_on:
- db
- redis
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:5000 || exit 1"]
interval: 30s
timeout: 5s
retries: 3
start_period: 10s
redis:
image: redis:8
ports:
- "6379:6379"
networks:
- elven
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 30s
timeout: 5s
retries: 3
start_period: 10s
db:
image: postgres:15
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: senhafacil
POSTGRES_DB: postgres
ports:
- "5432:5432"
networks:
- elven
volumes:
- pgdata:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 30s
timeout: 5s
retries: 3
start_period: 10s
networks:
elven:
driver: bridge
volumes:
pgdata:
Aplicação Python
-
Conectada ao Postgres e Redis via variáveis de ambiente
-
Porta 5001 → redireciona para o 5000 interno
-
Healthcheck ativo
-
Volume montado para desenvolvimento hot-reload
Redis
-
Imagem oficial Redis 8
-
Porta 6379 exposta
-
Healthcheck respondendo ao
PING
Postgres
-
Persistência com volume
pgdata -
Healthcheck com
pg_isready
Rede interna
elven(bridge) unindo os 3 serviços
Subindo toda a stack
1
docker-compose up -d
Acesso:
Pode ser realizado pelo navegado por localhost ou por um curl no localhost, resutado esperado é ver uma mensagem “App on”.
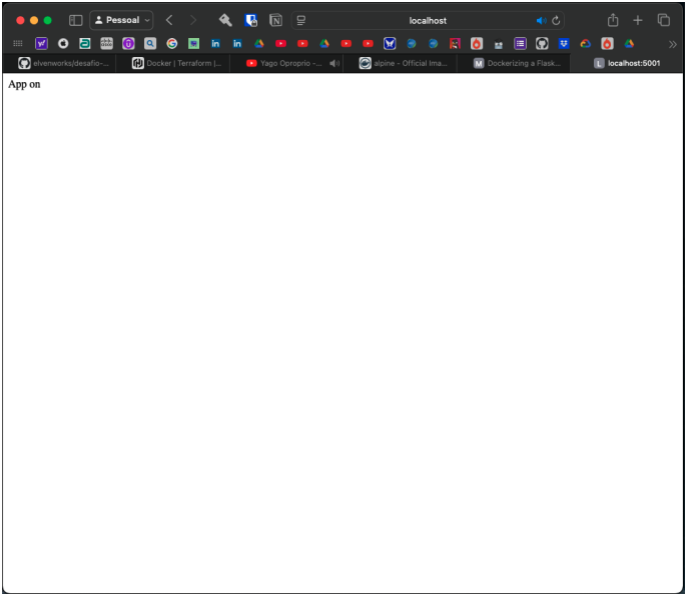
Para ver os Logs e derrubar a infra:
1
docker-compose logs -f app-elven
ou
1
docker-compose down
Subindo a imagem para o Registry:
1
docker login
1
docker tag app-elven:latest seuusuario/app-elven:latest
Puxando a imagem para o Registry:
1
docker push seuusuario/app-elven:latest
Problemas:
-
**Problemas com build por falta do compilator de extensão C:
1
Solução: no lugar de fazer multistage com duas fases de build foi feito apenas uma fase e instalado o gcc libpq-dev: ``apt-get install -y gcc libpq-dev``
-
Healthcheck da aplicação falhando: A aplicação subia mais devagar do que o tempo estipulado no healthcheck, problema solucionado colocando o “
start_period: 10s”
Criando o main.tf para criação do kind localmente.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
terraform {
required_providers {
kind = {
source = "loft-sh/kind"
version = "0.4.0"
}
}
}
provider "kind" {}
# Criação do cluster Kind
resource "kind_cluster" "kind" {
name = "kind-elven"
wait_for_ready = true
node_image = "kindest/node:v1.30.0"
# Configuração do cluster Kind (equivalente ao kind.yaml)
config = <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- role: worker
- role: worker
EOF
}
output "kubeconfig_file" {
value = kind_cluster.kind.kubeconfig_path
}
Iniciando o Terraform:
1
terraform init
Criando o cluster:
1
terraform apply -auto-approve
Verificando o cluster:
1
kubectl get nodes -A
Kubernetes utilizando o KIND localmente.
A aplicação foi provisionada localmente em um cluster KIND contendo:
-
App Flask
-
Redis
-
Postgres
-
Ingress NGINX
-
Prometheus + Grafana via Helm (kube-prometheus-stack)
-
Regras personalizadas
-
Monitoramento via ServiceMonitor
Toda a stack rodou dentro do namespace desafio-sre e o monitoramento no namespace monitoring.
Criação Namespace:
1
kubectl create namespace desafio-sre
Aplicação – Deployment
Arquivo: app-deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
apiVersion: apps/v1 #Sempre vai ser apps/v1
kind: Deployment #Tipo do manisfesto
metadata:
labels:
app: app-sre
name: app-sre
namespace: desafio-sre
spec: #caracteristicas do deployment
replicas: 3
selector: #Controla os Pods referentes a essa aplicação
matchLabels: #Todos os Pods que tiverem a mesma label é esse deployment que vai cuidar
app: app-sre
strategy: #Estrategias de deployment
type: RollingUpdate #Estrategia de atualização
rollingUpdate:
maxSurge: 1 # Pode ter até 1 pod a mais do que eu pedi
maxUnavailable: 2 #Vai atualizar de 2 em 2
template: #Template criado para o POD
metadata:
labels:
app: app-sre
spec: # Caracteristica agora do meu POD/Container
containers:
- image: thallysonyakko/desafiosre:1.0
env: #Variaveis de ambiente DB-postgres
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret #Nome do postgres-secret
key: POSTGRES_PASSWORD
- name: POSTGRESS_DB
valueFrom:
secretKeyRef:
name: postgres-secret #Nome do postgres-secret
key: POSTGRES_DB
- name: POSTGRESS_USER
valueFrom:
secretKeyRef:
name: postgres-secret #Nome do postgres-secret
key: POSTGRES_USER
name: app-sre
resources: #Resources do meu POD e seus limits
limits:
cpu: "0.8"
memory: "256Mi"
requests:
cpu: "0.3"
memory: "64Mi"
livenessProbe: # Tipo de helthcheck
httpGet:
path: / #Pasta raiz
port: 5000
initialDelaySeconds: 10 #Tempo que vai esperar até testar a primeira probes
periodSeconds: 10 # De quanto em quanto tempo ele vai testar
timeoutSeconds: 5
failureThreshold: 3 # Após 3 vezes ele vai tentar restartar o POD
Principais pontos:
-
3 réplicas da aplicação
-
Variáveis de ambiente para Postgres e Redis
-
Porta 5000 exposta
-
Readiness/Liveness probes podem ser adicionados posteriormente
Comando aplicado:
1
kubectl apply -f app-deployment.yaml -n desafio-sre
Aplicação - Service
Arquivo: app-service.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
apiVersion: v1
kind: Service
metadata:
name: app-sre
namespace: desafio-sre
labels:
app: app-sre
env: dev
spec:
selector: #Quais pods vão ser expostos
app: app-sre #Seleciona os Pods com essa label
ports:
- port: 5000 #Porta do serviço
name: http
targetPort: 5000 #A porta onde o cluster tá escutando
type: ClusterIP
Service ClusterIP:
1
kubectl apply -f app-service.yaml -n desafio-sre
Redis - Deploy, Service e Secret:
Arquivo: redis-deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
apiVersion: apps/v1 #Sempre vai ser apps/v1
kind: Deployment #Tipo do manisfesto
metadata:
labels:
app: redis
name: redis
namespace: desafio-sre
spec: #caracteristicas do deployment
replicas: 2
selector: #Controla os Pods referentes a essa aplicação
matchLabels: #Todos os Pods que tiverem a mesma label é esse deployment que vai cuidar
app: redis
strategy: #Estrategias de deployment
type: RollingUpdate #Estrategia de atualização
rollingUpdate:
maxSurge: 1 # Pode ter até 1 pod a mais do que eu pedi
maxUnavailable: 1 #Vai atualizar de 2 em 2
template: #Template criado para o POD
metadata:
labels:
app: redis
spec: # Caracteristica agora do meu POD/Container
containers:
- image: redis:7
name: redis
resources: #Resources do meu POD e seus limits
limits:
cpu: "0.8"
memory: "500Mi"
requests:
cpu: "0.3"
memory: "256Mi"
Arquivo: redis-secret.yaml
1
2
3
4
5
6
7
8
9
apiVersion: v1
kind: Secret
metadata:
name: redis-secret
namespace: desafio-sre
type: Opaque
data:
redis-password: ZGVzYWZpb2VsdmVu # "desafioelven"
Arquivo: redis-service.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: v1
kind: Service
metadata:
name: redis-service
namespace: desafio-sre
labels:
app: redis
env: dev
spec:
selector: #Quais pods vão ser expostos
app: redis #Seleciona os Pods com essa label
ports:
- port: 6379 #Porta do serviço
name: http
targetPort: 6379 #A porta onde o cluster tá escutando
type: ClusterIP
Aplicando:
1
kubectl apply -f ./REDIS -n desafio-sre
Problemas enfrentados:
YAML com erro de indentação
yaml: line 25: mapping values are not allowed in this context
➜ Ajustado o redis-deployment.yaml.
Service sem nome (“resource name may not be empty”)
Corrigido para:
metadata: name: redis-service
Postgress
Arquivo: postgres-deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
apiVersion: apps/v1 #Sempre vai ser apps/v1
kind: Deployment #Tipo do manisfesto
metadata:
labels:
app: postgres
name: postgres
namespace: desafio-sre
spec: #caracteristicas do deployment
replicas: 2
selector: #Controla os Pods referentes a essa aplicação
matchLabels: #Todos os Pods que tiverem a mesma label é esse deployment que vai cuidar
app: postgres
strategy: #Estrategias de deployment
type: RollingUpdate #Estrategia de atualização
rollingUpdate:
maxSurge: 1 # Pode ter até 1 pod a mais do que eu pedi
maxUnavailable: 1 #Vai atualizar de 2 em 2
template: #Template criado para o POD
metadata:
labels:
app: postgres
spec: # Caracteristica agora do meu POD/Container
containers:
- image: postgres:15
name: postgres
envFrom:
- secretRef:
name: postgres-secret
resources: #Resources do meu POD e seus limits
limits:
cpu: "0.8"
memory: "500Mi"
requests:
cpu: "0.3"
memory: "256Mi"
Arquivo: postgres-secret.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
namespace: desafio-sre
type: Opaque
data:
POSTGRES_DB: ZGVzYWZpbw== # desafio
POSTGRES_USER: cG9zdGdyZXM= # postgres
POSTGRES_PASSWORD: MTIzNDU2 # 123456
POSTGRES_HOST: cG9zdGdyZXMtc2VydmljZQ== # postgres-service
POSTGRES_PORT: NTQzMg== # 5432
Arquivo: postgres-service.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: v1
kind: Service
metadata:
name: postgres-service
namespace: desafio-sre
labels:
app: postgres
env: dev
spec:
selector: #Quais pods vão ser expostos
app: postgres #Seleciona os Pods com essa label
ports:
- port: 5432 #Porta do serviço
name: http
targetPort: 5432 #A porta onde o cluster tá escutando
type: ClusterIP
Aplicando:
1
kubectl apply -f ./POSTGRES -n desafio-sre
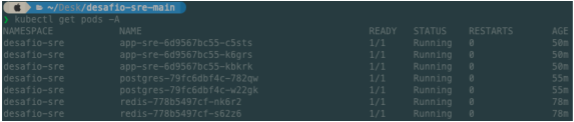
Conferência dos Pods
1
kubectl get pods -A
Configurações do ingress no cluster
- Crie um arquivo chamado
kind-config.yamlcom o conteúdo abaixo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
- Em seguida, crie o cluster usando este arquivo de configuração:
1
kind create cluster --config kind-config.yaml
Instalando o Ingress Nginx Controller
- Super importante fazer a instalação através do HELM.
- Instalação:
1
2
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/provider/kind/deploy.yaml
- Comando de condição:
Pods condition ready
1 2 3 4
kubectl wait --namespace ingress-nginx \ --for=condition=ready pod \ --selector=app.kubernetes.io/component=controller \ --timeout=90s
Criando a primeira regra:
- Precisa criar um yaml para o ingress:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: desafio-sre-ingress
namespace: desafio-sre
annotations:
nginx.ingress.kubernetes.io/rewrite-target: / #Rewrite= Rescreva, idenpendente do que for passado ele vai redirecionar para o /
spec:
rules:
- host: app.elven.works #Criando um dns na minha maquina, preciso modificar no /etc/hosts para passar esse "dominio" par o meu local hostt
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: app-sre
port:
number: 5000
---
#---------
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: monitoring-ingress
namespace: monitoring
spec:
rules:
- host: grafana.elven.works
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-stack-grafana
port:
number: 80
- host: prometheus.elven.works
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-stack-kube-prom-prometheus
port:
number: 9090
- Aplicando:
kubectl apply -f ingress.yaml
- Verificando o Ingress:
kubectl get ingress
Teste Ingress:
-
Via Navegador:
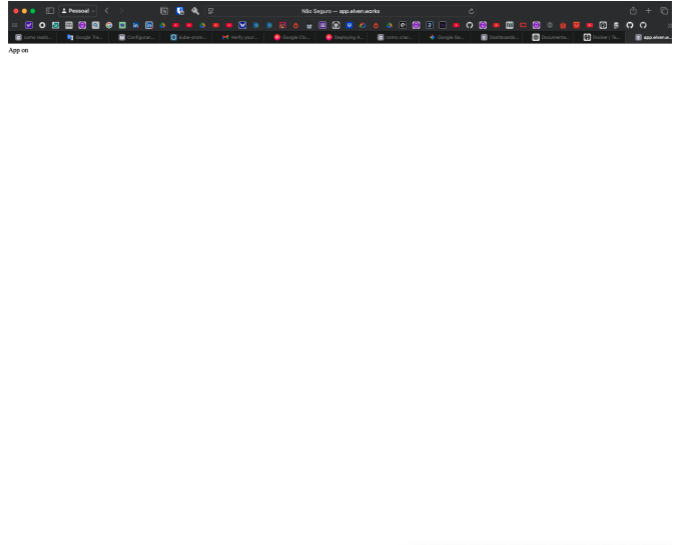
-
Via cli:

Instalação do Prometheus via Helm:
1
2
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
- Criando o namespace:
1
kubectl create namespace monitoring
- Instalando:
1
helm install prometheus-stack prometheus-community/kube-prometheus-stack -n monitoring
- Verificando:
1
kubectl get pods -n monitoring
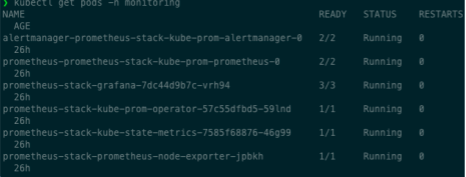
Acessando o Grafana via Ingress:
-
Navegador:
url: grafana.elven.works -
Dashboards
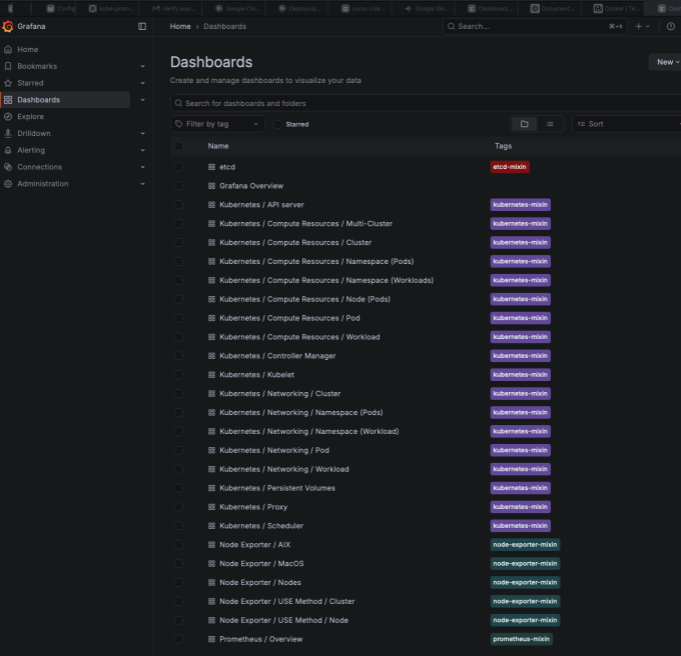
- Métricas do cluster:
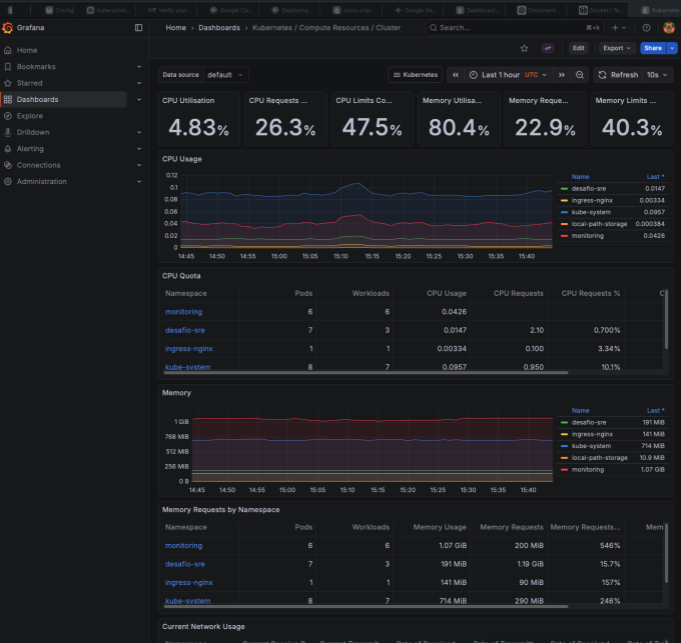
- Secrets:
1
kubectl get secret prometheus-stack-grafana -n monitoring -o jsonpath='{.data.admin-password}' | base64 --decode
- Prometheus acesso via ingress:
url:prometheus.elven.works
Criando ServiceMonitor da aplicação:
Arquivo: app-sre-monitor.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: app-sre-monitor
namespace: monitoring # O ServiceMonitor DEVE estar no mesmo namespace do Prometheus
labels:
release: prometheus-stack # Importante: Selecionar o Prometheus Operator
spec:
namespaceSelector:
matchNames:
- desafio-sre # O namespace onde sua aplicação está
selector:
matchLabels:
app: app-sre # Use o rótulo do seu Service (verifique o Service 'app-sre' para o rótulo correto)
endpoints:
- port: http-metrics # Nome da porta (deve ser definido no seu Service, veja nota abaixo)
path: /metrics # O caminho onde as métricas estão (ex: /metrics ou /actuator/prometheus)
interval: 30s # Frequência de coleta (opcional)
Aplicando:
1
2
kubectl apply -f app-sre-monitor.yaml
Criando o Prometheusrules:
Arquivo: prometheus-gold-rules.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: application-gold-alerts
namespace: monitoring # Altere se seu PrometheusRule estiver em outro namespace
labels:
prometheus: k8s
role: alert-rules
app.kubernetes.io/name: application-gold
spec:
groups:
# ----------------------------------------------------
# GRUPO 1: REGRAS GOLD PARA APLICAÇÃO FLASK (flask-app)
# ----------------------------------------------------
- name: flask.gold.alerts
rules:
# [G/D] - Get/Duration: Alta Taxa de Erros (5xx)
- alert: FlaskHighErrorRate
expr: |
sum(rate(http_requests_total{job="flask-app", code=~"5xx"}[5m]))
/
sum(rate(http_requests_total{job="flask-app"}[5m]))
> 0.05 # Mais de 5% de erros de servidor
for: 3m
labels:
severity: critical
annotations:
summary: "Flask: Taxa de Erros 5xx Acima do Limite ({{ $value | printf \"%.2f%%\" }})"
description: "Mais de 5% das requisições resultaram em erro de servidor nas últimas 3 minutos."
# [O] - Output: Alta Latência P95
- alert: FlaskHighLatencyP95
expr: |
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket{job="flask-app"}[5m])) by (le))
> 0.8 # Latência P95 acima de 800ms
for: 5m
labels:
severity: warning
annotations:
summary: "Flask: Latência P95 Acima do Limite ({{ $value | printf \"%.3f\" }}s)"
description: "O 95º percentil de requisições está lento por 5 minutos, afetando a experiência do usuário."
# [L] - Load: Queda Súbita de Tráfego
- alert: FlaskTrafficDrop
expr: |
sum(rate(http_requests_total{job="flask-app"}[5m]))
<
(
sum(rate(http_requests_total{job="flask-app"}[30m] offset 5m))
* 0.2
)
for: 5m
labels:
severity: warning
annotations:
summary: "Flask: Queda Súbita de Tráfego"
description: "O RPS caiu mais de 80% em comparação com os 30 minutos anteriores. Pode indicar uma falha de serviço ou de coleta de métricas."
# ----------------------------------------------------
# GRUPO 2: REGRAS GOLD PARA REDIS (redis-exporter)
# ----------------------------------------------------
- name: redis.gold.alerts
rules:
# [G] - Get: Verificação de Saúde (up)
- alert: RedisDown
expr: up{job="redis"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Redis: Serviço Inativo"
description: "O Prometheus não consegue raspar (scrape) o exporter do Redis por mais de 1 minuto. Instância: {{ $labels.instance }}"
# [O] - Output: Alta Utilização de Memória (Overhead)
- alert: RedisMemoryHigh
expr: redis_memory_used_bytes{job="redis"} / redis_total_system_memory_bytes{job="redis"} > 0.85
for: 10m
labels:
severity: warning
annotations:
summary: "Redis: Memória Utilizada Excedeu 85%"
description: "O Redis está próximo de atingir o limite de memória. Valor atual: {{ $value | humanizePercentage }}"
# ----------------------------------------------------
# GRUPO 3: REGRAS GOLD PARA POSTGRESQL (postgres-exporter)
# ----------------------------------------------------
- name: postgres.gold.alerts
rules:
# [G] - Get: Verificação de Saúde (up)
- alert: PostgresDown
expr: up{job="postgres"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "PostgreSQL: Serviço Inativo"
description: "O Prometheus não consegue raspar (scrape) o exporter do PostgreSQL por mais de 1 minuto. Instância: {{ $labels.instance }}"
# [D] - Duration/Details: Bloqueios no Banco de Dados (Deadlocks)
- alert: PostgresDeadlocks
expr: rate(pg_stat_database_deadlocks{job="postgres"}[5m]) > 0
for: 2m
labels:
severity: critical
annotations:
summary: "PostgreSQL: Deadlocks Detectados"
description: "Foram detectados deadlocks no banco de dados nas últimas 5 minutos. Isso requer atenção imediata."
# [L] - Load: Muitas Conexões Ativas (Pode causar esgotamento de recursos)
- alert: PostgresTooManyConnections
expr: pg_stat_activity_count{datname="mydatabase"} > 100 # Exemplo: mais de 100 conexões ativas
for: 5m
labels:
severity: warning
annotations:
summary: "PostgreSQL: Excesso de Conexões"
description: "O banco de dados 'mydatabase' tem mais de 100 conexões ativas. Valor: {{ $value }}. Revise o pool de conexões da aplicação."
Aplicando:
1
2
kubectl apply -f prometheus-gold-rules.yaml -n monitoring
Conferencia:
1
2
kubectl get prometheusrules -n monitoring
-
Esse foi o resultado da primeira semana do desafio em que tinha que ser desenvolvido:
- Rodar a aplicação na máquina
- Dockernizar essa aplicação e provisionar
- Provisionar a app usando o terraform local na maquina
- Usar kind para provisionar a mesma
- Monitorar o cluster local com prometheus + grafana (instalação via helm)